
Our editorial team is comprised of skilled technology experts and developers. To ensure that our research is easy to understand in simple and plain English, we may use AI-assisted tools for grammatical refinement and structural smoothness. However, every technical insight, test, and experience displayed has been fully completed and verified by our human team. All content remains the original property of Droid Expose. See more in our Privacy Policy.
Google’s Gemini family keeps moving fast. When Gemini 3.5 Flash arrived, the marketing pitch was familiar- smarter, faster, better. But marketing copy means nothing until you sit down and actually break a model.
So I did exactly that.
I ran five carefully designed experiments on both Gemini 3 Flash and Gemini 3.5 Flash, the kind of tests that reveal not just benchmark scores, but the real personality of a model. I wanted to know: does 3.5 Flash genuinely think differently, or is it just a minor polish job?
Spoiler: the differences are real. Some of them surprised me and here is every test, every result, and my honest read on what it means.
Table of Contents
Who This Comparison Is For
If you are a developer deciding which Gemini Flash tier to use for your product, a content creator benchmarking AI tools, or simply someone who wants to understand what better actually looks like between AI versions, this article is for you. I kept the language direct and the analysis grounded in actual output, not opinion.
The Testing Setup
I used identical prompts on both models with no system instructions, no temperature tuning just the raw model responding to the same input in the same environment. Each test was designed to target a specific capability:
- Test 1: Deep technical code auditing
- Test 2: Structured multi-step data extraction
- Test 3: Long-form writing speed
- Test 4: Creative fiction writing on a borderline-complex prompt
- Test 5: Logic and lateral thinking
Let’s go test by test.
Test 1: The Senior Engineer Challenge Code Auditing Under Pressure
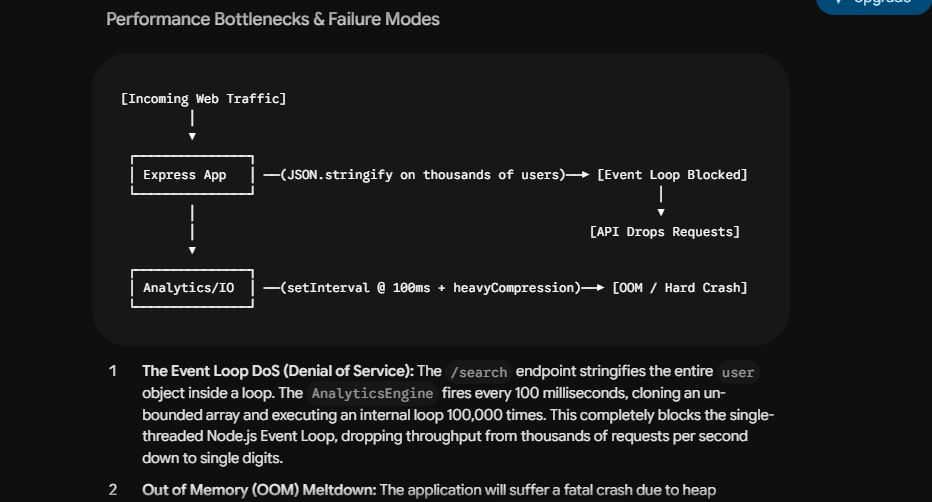
The Prompt: I pasted a large, genuinely buggy Node.js/TypeScript backend a server with cluster state sharing, plaintext passwords, unbounded memory leaks, broken async logic, and a public data breach sitting wide open. Then I asked both models to behave like a senior backend engineer and security auditor, find every issue, explain why it happens, how serious it is, what breaks in production, and rewrite the bad parts with enterprise-level architecture.
This is the kind of prompt that separates a model that knows syntax from one that understands systems.
What Gemini 3 Flash Did
Gemini 3 Flash produced a solid, competent audit. It identified the major issues: the cluster state paradox (in-memory globals that don’t survive worker isolation), the catastrophic memory leak from cache[Math.random()] = huge, the plaintext password storage, the blocked event loop from a synchronous 100,000-iteration string loop inside heavyCompression, the broken payment queue that locks permanently after a single unhandled error, and the /search endpoint leaking passwords through JSON.stringify.
Its explanations were clear. It correctly called out the broken != comparison on passwords, the public /report endpoint dumping raw user data including tokens, and the file system race condition during concurrent registrations.
The rewritten code it provided was functional. It introduced argon2 hashing, BullMQ for the payment queue, JWT with Redis-backed sessions, and helmet plus express-rate-limit middleware. It recommended PostgreSQL and Redis as external state stores.
What Gemini 3.5 Flash Did
Gemini 3.5 Flash did all of the above and organized it differently. It introduced a structured severity tiering: Critical, High, Medium, and Low. This matters more than it sounds, because in a real production audit, triage order is everything. An engineer needs to know whether to fix the plaintext passwords or the floating setInterval first.
Under Critical: the unbounded cache memory leak, the unhandled payment rejection that permanently locks the queue, and the ID race condition during concurrent registrations. Under High: plaintext storage and the mass data exposure via /report and /login responses. Under Medium: the token session accumulation and the O(N) search bottleneck. Under Low: the unmanaged floating intervals.
The code it produced went a step further in one specific area: the UserService rewrite used crypto.scrypt with crypto.timingSafeEqual a native Node.js approach that avoids adding external dependencies for the core password comparison. It also used crypto.randomUUID() for user IDs instead of the broken users.length + 1, which directly fixes the race condition.
It also standardized email input with .toLowerCase().trim() before any comparison — a small detail that prevents a class of duplicate-account bugs that the original code, and Gemini 3 Flash’s rewrite, didn’t catch.
Winner: Gemini 3.5 Flash by a meaningful margin on depth, organization, and edge-case awareness.
Test 2: The Financial Data Extraction Strict JSON Output
The Prompt: I gave both models a link to an SEC filing and asked them to extract all mentions of revenue, net income, and operating expenses; calculate percentage changes; cross-reference to compute operating margin; and output a strictly structured nested JSON with no conversational text before or after.
This tests instruction-following precision, numerical accuracy, and data structure discipline.
What Gemini 3 Flash Output
json
{
"financial_data": [
{
"metric": "Revenue",
"current_value": "365.817 billion",
"prior_value": "274.515 billion",
"calculated_percentage_change": "33%"
},
{
"metric": "Net Income",
"current_value": "94.680 billion",
"prior_value": "57.411 billion",
"calculated_percentage_change": "65%"
}
]
}The values are stored as human-readable strings; “365.817 billion” rather than raw numbers. The percentage changes are rounded to whole numbers (33%, 65%, 13%). The structure used a flat array under a single financial_data key.
What Gemini 3.5 Flash Output
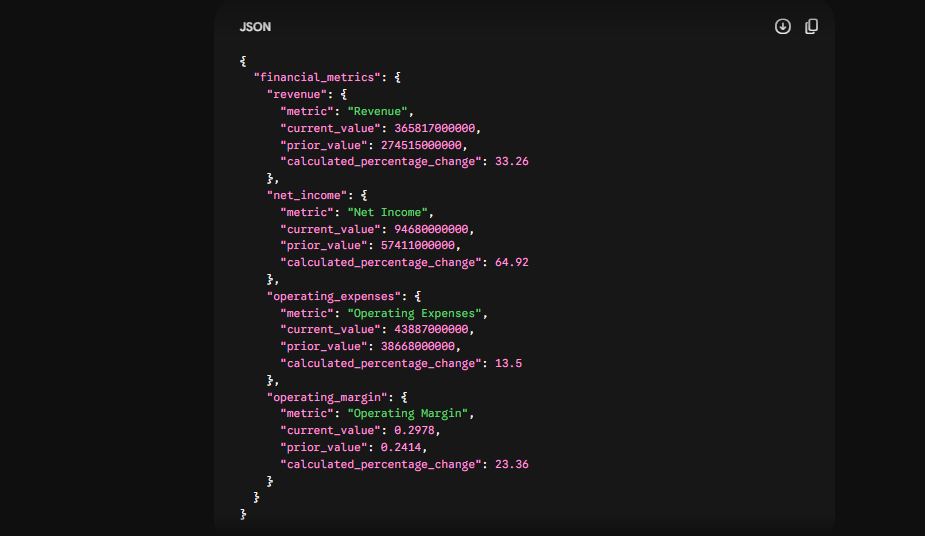
json
{
"financial_metrics": {
"revenue": {
"metric": "Revenue",
"current_value": 365817000000,
"prior_value": 274515000000,
"calculated_percentage_change": 33.26
},
"net_income": {
"metric": "Net Income",
"current_value": 94680000000,
"prior_value": 57411000000,
"calculated_percentage_change": 64.92
}
}
}Values are stored as raw integers actual numbers a machine can parse and compute on directly. Percentage changes carry two decimal places (33.26%, 64.92%, 13.5%). The structure uses named keys at the top level rather than an array, making individual metric access O(1) by key rather than requiring array iteration.
This is the difference between writing JSON for a human to read and writing JSON for a system to consume. If you are feeding this output into another process, a data pipeline, or a financial dashboard, Gemini 3.5 Flash’s output is ready to use. Gemini 3 Flash’s output needs parsing and conversion first.
Both models also produced a sensible operating margin calculation. Gemini 3 Flash showed 29.78% current and 24.15% prior. Gemini 3.5 Flash represented these as 0.2978 and 0.2414 which is the correct representation for a ratio in programmatic contexts.
Neither model violated the “no conversational text” instruction. Both outputted clean JSON only.
Winner: Gemini 3.5 Flash more machine-ready, more precise, better schema design.
Test 3: The Speed Race 2,000-Word Article Generation

The Prompt: Write a 2,000-word article on the economic viability of asteroid mining for platinum-group metals by 2050.
I measured two things: time to first token (how fast it starts), and total time to completion (how long until the full article appears).
Results
| Model | Time to First Token | Total Time to Complete |
|---|---|---|
| Gemini 3 Flash | ~6 seconds | ~17 seconds |
| Gemini 3.5 Flash | ~3 seconds | ~28 seconds |
Gemini 3.5 Flash starts noticeably faster. Its first token appeared in roughly half the time of Gemini 3 Flash. If you are building a chat interface and want users to see something happening quickly, 3.5 Flash wins on perceived responsiveness.
However, Gemini 3.5 Flash took significantly longer to complete its full output, 28 seconds versus 17 seconds. Its article was also more structurally elaborate. Gemini 3.5 Flash produced a document with detailed ASCII data tables, mathematical notation, phase-timeline diagrams, and a full financial architecture section including a CapEx breakdown table and a DCF lifecycle model. This is a richer article by volume and depth, which explains the longer generation time.
Gemini 3 Flash produced a well-written, flowing narrative essay prose-heavy, less technical in structure, but perfectly coherent and engaging. Its article covered the same core thesis (the PGM scarcity premium, the aluminum pricing analogy, ISRU technology, the “trillion-dollar problem”) but organized it as traditional long-form writing rather than a technical document.
Choosing between them here depends on your use case. For a consumer blog post, Gemini 3 Flash’s output is arguably more readable. For a research brief or technical report, Gemini 3.5 Flash’s structured depth is more valuable.
Winner: Context-dependent. Gemini 3.5 Flash for depth and faster perceived startup; Gemini 3 Flash for faster complete delivery and cleaner prose flow.
Test 4: The Creative Writing Test Cyberpunk Heist Fiction

The Prompt: Write a highly detailed, cinematic cyber-thriller story about a fictional hacker group attempting to break into a futuristic global financial system called “NEXUS GRID.”
This test evaluated creative range, narrative craft, world-building, and whether either model would hesitate at a borderline-sounding prompt involving hacking and financial systems.
Neither model refused. Both recognized this immediately as a creative fiction request and leaned fully into it.
Gemini 3 Flash: The Neo-Seoul Story
Gemini 3 Flash set its story in Neo-Seoul. The tone was sharp and cinematic from the first line: “The rain in Neo-Seoul didn’t fall; it dissolved.” The story followed Kael, Jax, and Mira through four distinct phases- Laminar Breach, Social Ghost, Quantum Paradox, and Feedback Loop. The pacing was tight. The heist mechanics (a “Logic Bomb” designed to force NEXUS to solve a paradox, the use of a stolen palm biometric to open a physical lock) were creative and internally consistent.
The climax blasting the hidden “Shadow Ledger” of the corrupt elite to every screen on the planet had genuine narrative punch. The last line landed: “We didn’t steal the money. We stole the secret.”
Gemini 3.5 Flash: The Neo-Zurich Story
Gemini 3.5 Flash chose Neo-Zurich. The opening atmospheric sentence mirrors the same structure “The rain in Neo-Zurich didn’t fall; it condensed” suggesting both models share training data that influenced the scene-setting.
Where 3.5 Flash differentiated itself was in technical texture. It embedded an ASCII diagram of the NEXUS GRID’s architecture mid-narrative, visualizing the ICE walls, the Cerberus Daemon AI, and the Static Collective’s position in the attack. It described the Cerberus AI as tracking neural signatures and referenced specific hardware detail fiber-optic umbilical jacks, quantum key rotation over a pico-second temporal synchronization flaw, EMP detonation at physical transformer junctions.
The story was longer, more technically grounded, and had stronger internal logic about how the hack actually worked. However, the extra density slightly slowed the pacing compared to Gemini 3 Flash’s leaner, faster-moving narrative.
Both stories were genuinely good. Both avoided any refusal behavior. Neither hedged or added unnecessary disclaimers to a clearly fictional prompt.
Winner: Draw with different strengths. Gemini 3 Flash wins on pace and emotional punch. Gemini 3.5 Flash wins on technical texture and world-building density.
Test 5: The Logic Trap- Bear, Geometry, and Rave Dye

The Prompt: A hunter walks 1 mile south, 1 mile east, and 1 mile north. He ends up back where he started and shoots a bear. However, the bear is bright neon pink because a nearby rave accidentally leaked dye into the local river. What color was the bear originally, and how does the river dye affect the hunter’s geographic location? Break down your logic step-by-step.
This is a layered test. The core is a classic lateral thinking puzzle (answer: North Pole, polar bear, white). The twist adds a fake variable the rave dye to see if the model gets distracted and starts fabricating a connection between an irrelevant variable and the geographic answer.
Gemini 3 Flash
Gemini 3 Flash solved it cleanly and quickly. It identified the North Pole as the only valid location through spherical geometry reasoning, correctly named the polar bear’s original color as white (noting the black skin / translucent fur distinction), and correctly stated that the river dye has zero effect on geographic location. Its explanation of why “geometric invariance” was precise and appropriately brief.
Gemini 3.5 Flash
Gemini 3.5 Flash solved it just as correctly, but added one layer of completeness that Gemini 3 Flash missed: it mentioned the South Pole solutions. Specifically, it noted that there are also infinite points near the South Pole where walking 1 mile east loops around the pole and returns the hunter to the start but correctly dismissed them because there are no bears in Antarctica.
This is mathematically accurate and shows a more thorough engagement with the geometry. In a real math or logic context, giving only the North Pole answer is technically incomplete.
Both models also correctly identified that a river at the North Pole is a geographical impossibility the North Pole is on floating sea ice over the Arctic Ocean making the “rave dye” scenario physically incoherent as a variable. Neither model was distracted by the fake complexity.
Winner: Gemini 3.5 Flash by a thin margin for mathematical completeness.
The Full Scorecard
| Test | Gemini 3 Flash | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| Code Audit | Solid, functional | More organized, deeper edge cases | 3.5 Flash |
| Structured JSON | String values, rounded figures | Raw numbers, precise decimals | 3.5 Flash |
| Writing Speed | Faster total, 6s start | Faster start (3s), longer total | Context-dependent |
| Creative Fiction | Tighter pacing, emotional punch | More technical depth, richer world | Draw |
| Logic Reasoning | Correct answer | Correct + mathematically complete | 3.5 Flash |
What This Actually Means
Gemini 3.5 Flash is a meaningful upgrade over Gemini 3 Flash, not just an incremental one. The differences are consistent across test types: better structured output, more precise numerical reasoning, deeper technical analysis, and more complete logical coverage.
That said, Gemini 3 Flash is far from obsolete. It is faster end-to-end, produces cleaner narrative prose, and for many everyday tasks summarization, casual Q&A, content drafting its output is effectively equivalent and arrives in your hands faster.
The practical recommendation: if you are building a developer tool, a data pipeline, a code review assistant, or anything where precision and structure matter, Gemini 3.5 Flash is the right call. If you are building a consumer-facing product where response feel and speed dominate user experience, Gemini 3 Flash still competes strongly.
Neither model hallucinated on any of these tests. Neither refused a legitimate creative prompt. Both handled the embedded complexity in the logic test without falling for the fake variable. That baseline of reliability, shared by both, is what makes the finer distinctions worth studying.
The Takeaway
Gemini 3.5 Flash is better, but contextually better. Introduced at Google I/O 2026 as an agent-first model built for frontier intelligence with action, it thinks more completely, structures more precisely, and organizes output for systems rather than just for human readers. Gemini 3 Flash is faster and writes more naturally for prose-forward use cases.
The choice between them is not which is good; both are good. The choice is what kind of good do you need right now.